
SEDA is a modular data layer that sets a standard for modular data transport and queries for any data type for all networks. SEDA’s data layer allows protocols to issue intents that power chain-abstracted data queries from any source. But what does that mean? Don’t worry; we will break it down, including a full suite of critical Web3 features built into SEDA, including:
- Chain-agnostic design
- Permissionless access
- Non-App specific composability
- Modular Design
- Intent Enabled
SEDA also incorporates bespoke functions such as fair OEV distribution mechanics and customizable data pricing models. In this blog, we will dive into the meaning and function of each ‘buzzword,’ resulting in a crystal clear understanding of ‘what & why SEDA.’
What Problems is SEDA solving?
SEDA solves The Oracle Problem and associated Web3 data transport problems, upgrading the current blockchain data infrastructure.
The Oracle Problem
Blockchains are completely isolated networks from the real world. This means that to connect with real-world data, they require a bridge to connect off-chain information. This is the Oracle problem at a high level: providing a solution for blockchains to access real-world data. However, there are issues within the Oracle problem, including deployment scalability, gatekeeping data, questionable pricing models, rigid data feed configuration, and more. SEDA was meticulously designed to address the Oracle problem and intrinsic issues, resulting in one modular layer for data access, transport, and configuration.
Deployment Scalability
Oracles must be natively deployed on each chain, setting up a data feed. It is estimated that 90% of smart contracts require some data input. With all the Blockchains in Web3, this has created a deployment bottleneck where integrations for major Oracles can be upwards of 6 months. This creates opportunities for infrastructure to prioritize larger, more popular projects for integration, leaving other, more minor protocols waiting for needed integration to boost traffic on their protocol.
Gatekeeping Data
Many Oracle solutions require protocols to be approved or whitelisted before they are allowed to begin integrating data feeds. Naturally, this results in delayed protocol growth and scalability. Often, projects are refused access to data feeds because Oracles assume there is insufficient traffic to warrant their feeds’ costly and timely integrations. It is also worth noting that this goes against the ethos of Web3, a philosophy built into SEDA’s permissionless makeup, which we will explore later in the blog.
Questionable Pricing Models
While many different pricing models exist for data feeds, data providers seek the most customizable approach to placing data on their feeds — therefore remaining in control of the value they create. As the connection between providers and consumers, Oracles have complete control over the pricing models, often extracting the most value for themselves.
Rigid Data Feed Configuration
How Oracles and data networks are designed also restricts the protocol’s ability to create custom parameters on their data feeds. Protocols have been required to code their configurations by creating new intelligent contracts from scratch, which can incur auditing and delays in integration times.
The Data Transport Problem
As mentioned above, Oracles require native deployment on each network. To send or query data cross-chain, networks must rely on 3rd party bridging protocols. In 2022 alone, bridging hacks led to USD 2 billion being drained from users. Bridges are incredibly insecure and face scalability issues, such as bottlenecks when high amounts of transactions are sent.
The Emerging Need For Intent-Based Data Networks
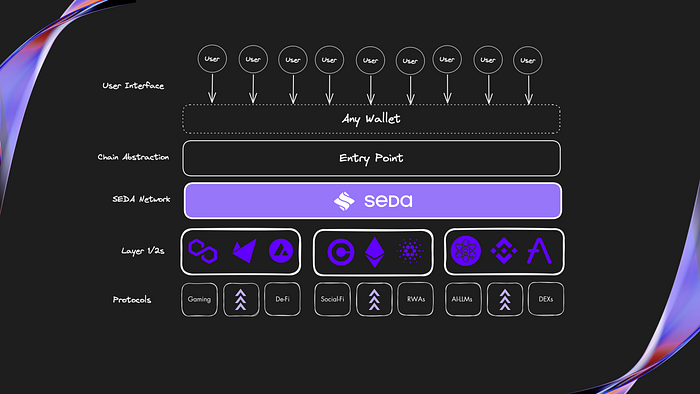
The need to execute broad intent-based actions will rise as Web3 shifts from monolithic, siloed blockchain environments to modular and chain-abstraction-enabled models. Currently, no data networks include intent-based faciliations within their design. While not intrinsically connected to the Oracle/data problem, intent-based networks will be in high demand as solvers working with chain abstracted layers require chain-agnostic pathways for client execution. Intents are detailed instructions that specific software can execute cross-chain on behalf of the user, mitigating the need for complex bridging and cross-chain actions by the user. We will explore intents later and how they power chain abstraction.
How Does SEDA Solve These Problems?
It is worth noting that many protocols have been built to solve one or two of the above solutions. However, SEDA is built to address ALL data transport and oracle-related issues to launch a new paradigm for Web3 data.
Below, we will break down each feature of SEDA that is within itself a critical solution to the aforementioned problems.
What Is A Data Layer, And How Does It Help SEDA Solve Oracle Problems?
To simplify data layers, imagine blockchains and data providers as houses in a new development without roads. To enable communication and information exchange, such as neighborhood weather, bridges were constructed for crossing between houses. However, each bridge had a guard checking whether owners were allowed to cross to exchange information (Centralized Oracles). As more and more houses (blockchains) were built, the network of bridges (Oracles) became overly complex and congested, leading to delays in bridge construction and bottlenecks (Information delays).
To solve this problem, the builders at SEDA came into the neighborhood and began deploying streets (The SEDA blockchain layer) with driveways (integration points) between all the houses. The new streets provided streamlined access to and from any house for an improved communication route between houses (Blockchains & data providers). The best part about the streets is that no one controls access to and from them, providing free-flowing communication. Like streets in this example, a data layer creates a ‘super highway’ that allows blockchains and data providers to plug and play simply, compared to relying on individual deployments to each destination.
How Does Being A Data Layer Help SEDA Solve Oracle & Data Problems?
SEDA’s comprehensive layer enables it to support all blockchains through a single integration per chain, eliminating the need for native deployment required by traditional data infrastructure. As a modular layer in the tech stack, SEDA facilitates unlimited connections between blockchains and data providers, acting as a Super Highway for any data query from any network source.
What Does Modular Mean, And How Does It Help SEDA Solve Oracle Problems?
Modular blockchains continue to dominate the Web3 narrative. For a separate dive into Modular blockchains, visit our dedicated blog here. Modularity means that a blockchain is built to focus on a specific function such as execution, data query, settlement, or others. For SEDA, this means data transport, access, and configuration. Modular blockchains can be interconnected via simple relay contracts (Messengers) to serve the function of one blockchain. This allows for a new era of development flexibility as builders can mix and match blockchains to meet their needs.
How Does Modularity Help SEDA Solve Oracle & Data Problems
As mentioned earlier, it’s estimated that 90% or more of smart contracts rely on data in some form. This is why we have seen Oracle technology massively improve the blockchain space. As an intent-based modular layer, SEDA is the natural evolution from Oracles. It allows builders to integrate SEDA within their Modular stack (a group of modular blockchains) to have a dedicated layer for accessing, querying, and configuring data requests. No more individual deployments; simply add SEDA via a SEDA relay contract to any modular tech stack for dedicated data needs.
What Does Intent-Based Mean, And How Does It Help SEDA Solve Oracle Problems?
Intents on SEDA are predefined instructions that facilitate data queries from any external blockchain, streamlining user interactions currently requiring step-by-step management. For example, to stake $x token from chain A to chain B, users must navigate through a complex process involving gas payments on both chains, connecting to a bridge, asset selection and approval, and multiple transaction confirmations. This overly complex process results in a poor user experience.
Intent-based networks, however, allow users to simply input their desired outcome as one predefined set of instructions, which, in the case above, is a stake $x token in this dApp/pool. Then, via a solver network, chain-abstracted layer, and a messenger contract, the back-end executes the transaction without the user needing to micro-manage each individual step; for them, it was simply click stake and be done.
Moving away from such a detailed-oriented design to broader intents is like setting a GPS to your desired destination without selecting the individual roads to travel.
How Does Intent-Centricity Help SEDA Solve Oracle & Data Problems?
SEDA, being intent-based, allows protocols to issue any data query of any data type from any network source. So, protocols can issue their intent to query any data type regardless of the network they are built on. An intent-based design allows SEDA to be a part of the chain abstraction tech stack, a critical concept in deploying intuitive and familiar UI/UX interfaces in Web3.
What Does Permissionless Mean, And How Does It Help SEDA Solve Oracle Problems?
Permissionless means that anybody, anywhere, can connect to a protocol/network without prior approval. Many Oracles and data networks are not inherently or natively 100% permissionless. This means that at some point, protocols can only integrate the infrastructure with prior approval from the Oracle/data network.
How Does Permissionless Access Help SEDA Solve Oracle & Data Problems
Remaining permissionless is a cornerstone of SEDA’s commitment to the Ethos of Web3, a completely open, decentralized, democratic internet. Protocols can simply integrate when they want without prior approval. Remaining permissionless also improves scalability for protocols as they can integrate with SEDA from 24 hours to a few days and access same-day data querying capabilities: no gatekeeping, no control, and pure freedom to build.
What Does Chain-Agnostic Mean, And How Does It Help SEDA Solve Oracle Problems?
Chain-Agnostic refers to a blockchain being able to communicate with any other blockchain. It’s similar to the idea of instant translating ear pods, where Person A speaks in Chinese and Person B hears the message in English. Now, both people can communicate without worrying about their languages (Blockchains). This would be referred to as a language-extracted conversation.
Within Web3, EVM and IBC chains can either interoperate or have similar code bases, allowing for simpler facilitation of interoperability mechanics. However, outside these groups, they require insecure bridges for cross-chain communication. Chain-Agnostiscm is achieved through unified APIs that facilitate interchain communication regardless of the code base they were built on.
How Do Chain-Agnostic Designs Help SEDA Solve Oracle & Data Problems
As you read above, traditional data networks and Oracles either require a native deployment to each blockchain they wish to serve or are restricted to the networks they operate (EVM or IBC, for example). SEDA’s native chain-agnostic design can provide services to any blockchain in any network, mitigating the need for insecure and high-risk associated third-party technologies like bridges or integration delays.
What Does Non-App Specific Mean, And How Does It Help SEDA Solve Oracle Problems?
Non-App specific means that SEDA does not restrict developers in what the network can be utilized for. As an intent-based modular data layer, SEDA can be added to any tech stack and programmed to suit the application’s data configuration requirements. In contrast, an app-specific blockchain is a blockchain that is built for one output only, such as gaming.
How Does Non-App Specific Designs Help SEDA Solve Oracle & Data Problems?
Non-app specificity unlocks endless use cases for developers adding SEDA into their tech stack. With the ability to scale horizontally via modular design, SEDA is naturally equipped to be the data layer building block within infinite amounts of app-specific blockchain applications yet to be built.
What Is OEV And Fair Distribution, And How Does It Solve The Oracle Problems?
OEV (Oracle Extractable Value) is the value that can be extracted by specific network participants who have early access to data updates. Imagine you see the BTC price feed update before anyone else. This would allow you to insert transactions before or after anyone else (known as frontrunning or back-running) to benefit from the BTC price feed update. This value that you extracted for yourself is known as OEV. Fair value distribution speaks to a network creating solutions that allow all participants to share profits extracted via OEV.
How Does OEV Distribution Help SEDA Solve Oracle & Data Problems?
By bundling OEV opportunities and auctioning them across the network, SEDA also can split the value across ALL network participants and consumers. Resulting in a fair market for all involved and removing unfair value extraction by unwanted network participants.
What Are Custom Pricing Models And How Does It Solve The Oracle Problems?
In this respect, custom pricing models refer to data providers being able to price their data against the market. Unlike subscription services, where Oracle networks can charge consumers 3–5x more than the provider’s price point, custom pricing models allow providers and protocols to fairly access only the data they use/provide at a competitive price, free of middleman networks extracting extra value for themselves.
How Do Custom Pricing Models Help SEDA Solve Oracle & Data Problems?
By incorporating this design, SEDA can organically facilitate a fair and competitive market for data providers without management. This model is also extremely attractive to data providers and consumers who have fallen victim to years of overpriced data feeds set by controlling third parties.
So, What Is An Intent-Based Modular, Permissionless, Chain-Agnostic, Non-App-Specific Data Layer with Fair OEV Distribution and Custom Pricing Models?
Combining all the above features into one data layer, the result is SEDA, one network for all things data. While many projects have aimed at solving one or two of the current data transport, access & configuration problems, SEDA was developed to be a comprehensive solution for the entire industry.
SEDA’s mainnet launch this quarter marks a much-awaited shift in Web3 data infrastructure, positioning SEDA as a leader in chain abstraction and modular design. This innovation promises unparalleled developer flexibility, making SEDA the dedicated data layer for the entire Web3 ecosystem.
One Network For All Things Data = SEDA The Modular Data Layer
SEDA
